supercised (정답을 알려주면서 학습하는 것 )의 classidication 분류 알고리즘 4가지

- LogisticRegression

from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.25, random_state= 1)
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state=N)
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
- K-NN _ KNeighbors
-- K 값을 바꿔서 성능이 제일 좋은 것을 선택한다


from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.25, random_state= 1)
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors= K)
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
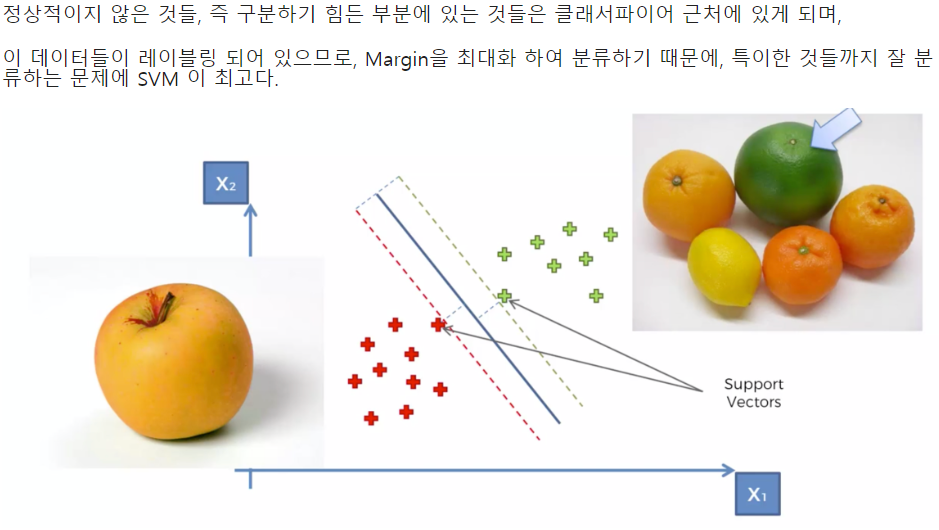
- SVM(Support Vector Machine)_SVC
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.25, random_state= 1)
from sklearn.svm import SVC
# kernel{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’} or callable, default=’rbf’
classifier = SVC(kernel='*')
y_pred = classifier.predict(X_test)
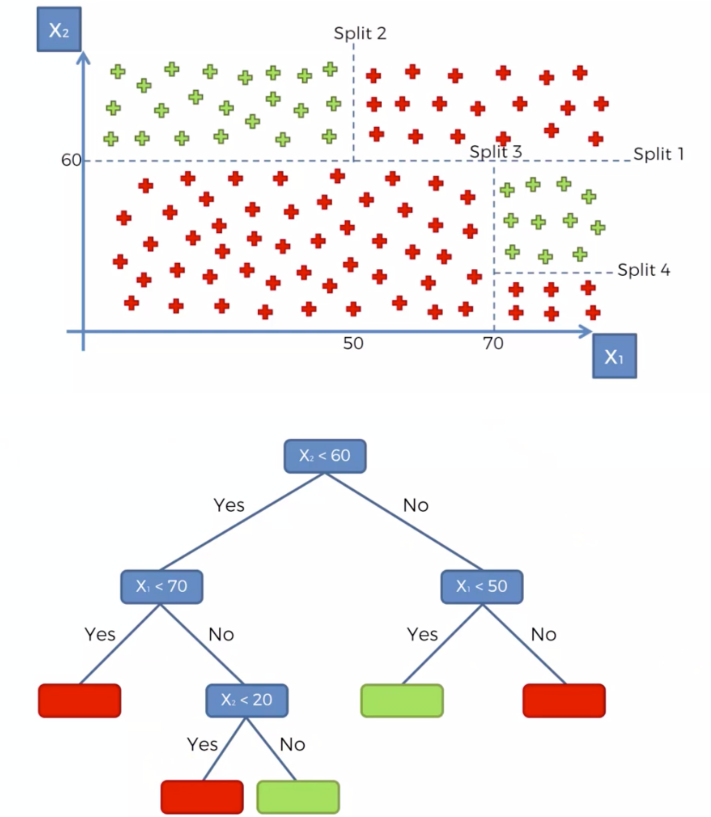
- DecisionTree
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.25, random_state= 1)
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier(random_state=N)
classifier.fit(X_train,y_train)
y_pred = classifier.predict(X_test)
4가지 방법 모두 train_test_split의 파라미터 값을 동일하게 만들고
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.25, random_state= 1)정확도를 측정하여 가장 좋은 것을 사용한다
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
cm
>>>
array([[NN, NN],
[NN, NN]], dtype=int64)
accuracy_score(y_test, y_pred)
# 0.NN
'MACHINE | DEEP LEARNING > Machine Learning Project' 카테고리의 다른 글
| [AI] 머신러닝 Unsupervised. K-Means Clustering와 반복문, 그룹 정보얻기 (0) | 2024.04.16 |
|---|---|
| [AI] 머신러닝 Unsupervised _평균군집 K-Means Clustering (0) | 2024.04.15 |
| [AI] 머신 러닝 데이터의 불균형 샘플링하는 방법 _ SMOTE를 활용한 오버샘플링 (0) | 2024.04.15 |
| [AI] 머신 러닝 LogisticRegressiond의 Confusion Matrix 성능 평가, 시본(seaborn)으로 분류 결과표 만들기 (0) | 2024.04.15 |
| [AI] 머신 러닝 피처 스케일링, train test 만들기, LogisticRegression 모델링 (0) | 2024.04.15 |



